Welcome back! I hope you enjoyed our session on CUDA! Missed it? Catch up here: How to Beat Your Dad At Camel Up (Part 3 – CUDA Baby!). If you’ve missed the whole series so far, start here: How to Beat Your Dad At Camel Up!
This is a continuation of our series on how to become a camel betting legend at your family games night. We’ve been using Python and C++ to dive deep into Camel Up over the last three articles. What’s new today? We’re going to harness the power of AI to play the game for us! How are we going to do that, you ask? We’re going to use reinforcement learning!
In this article I want to explain a little about reinforcement learning and how I’ve applied this to Camel Up. A word of warning – my agent won’t be conquering the world anytime soon. I clearly have a lot to learn! I do hope that this article will help you get started training your own AI agents. Let’s start by understanding more about reinforcement learning.
What is Reinforcement Learning?
Reinforcement learning is a machine learning technique to train AI “agents” to do tasks. It’s been used to create AI for a variety of games: from abstract games like Go to video games like Total War. Google’s AlphaGo was trained with reinforcement learning and beat the world champion of Go in 2016. Agents have also been created to play StarCraft II and Total War. Sounds impressive! But how does it work?
Throughout our lives, we’re often incentivized to behave in a certain way through rewards or punishment. For example, I give my cat a treat when he jumps through a hoop (what a good boy!). Reinforcement learning takes the same approach with tasks or games. It’s a technique used to find optimal behaviour through experience. Through many simulations, the agent makes choices and sees what reward or penalty they get. Over millions of plays, they understand what choices lead to the highest rewards!
In our situation, we want our agent to play Camel Up many times. On their turn they’re given the current board state: the position of the camels, what betting tiles are available, etc. They’re then asked to take an action. They can choose between the possible legal actions based on the board state. At first, the agent will just choose randomly and receives a reward based on its action. We then set it free to play LOTS of games, take actions randomly, and see how many points it gets.
To get technical for a moment, we’re going to use a certain type of reinforcement learning called Q-learning. This means that our agent keeps a lookup table, called a Q-table, where they lookup the current game state. The table contains the expected reward from each action based on prior experience. Each time it experiences a game, it will update this table with how it turned out. It learns over time! I guess that’s why they call it machine learning?
Which Reward?
The reward that we’re giving the agent is their score. As it’s a points-based game, I thought that most natural. There’s also a bonus / penalty for winning / losing respectively. This is just one of many choices, and I’ll probably change this as this project evolves. The rewards can be more arbitrary, like extra rewards for taking betting tiles over rolling the dice.
Implementing Reinforcement Learning in Python
This all sounds quite tricky, but never fear! Python is here! We’re going to make use of the gymnasium package maintained by the Farama Foundation. This package is a fork of OpenAI’s gym package and provides a useful framework for creating reinforcement learning agents. Let’s see how we apply this to our simulations.
Environment
To implement an agent we create a gymnasium environment. This runs a simulation of a game and asks the agent for an action when it’s their turn.
We define the environment in gym_env.py:
- Constructor: should set up the game for the first time and define key variables.
- reset method: Restarts the game from the beginning for the next simulation.
- step method: This is the most important method. This takes in the action from the agent and then simulates the game until the agent’s next turn. It calculates the reward for the agent based on how many points it accrued.
I needed to make some alterations to the core game code to make this work. The game needs to know when to pause for the agent to select an action. I added the “automated” attribute to the Player class so the game knew who to pause for. I also added the “run_stepped_turn” method to the Game object which simulates only until the next non-automated player turn.
Agent
The next part of our setup is to specify the agent. The agent needs to take in the current game state and return an action. We do this in the get_action method:
def get_action(self, obs: tuple[int, int, bool]) -> int:
"""
Returns the best action with probability (1 - epsilon)
otherwise a random action with probability epsilon to ensure exploration.
"""
# with probability epsilon return a random action to explore the environment
valid_action = False
while not valid_action:
if np.random.random() < self.epsilon:
proposed_action = env.action_space.sample()
# with probability (1 - epsilon) act greedily (exploit)
else:
proposed_action = int(np.argmax(self.q_values[obs]))
valid_action = env.unwrapped.action_mask[proposed_action]
logger.info(f"Taking action {env.unwrapped.action_mapping[proposed_action]}")
if hasattr(env.unwrapped.action_mapping[proposed_action], "color"):
logger.info(env.unwrapped.action_mapping[proposed_action].color)
return proposed_action
Reinforcement learning is a tug-of-war between exploring new options, and exploiting information already learned. The epsilon parameter controls the probability the agent chooses an action randomly (explores) or chooses what they think is the best option (exploit). We do need to make sure the action chosen is valid though. The agent can’t take a blue betting tile if there are none available!
We update the expected reward for each action based on the reward the agent receives for the action. This occurs in the update method where the Q-values (expected rewards) are adjusted:
def update(
self,
obs: tuple[int, int, bool],
action: int,
reward: float,
terminated: bool,
next_obs: tuple[int, int, bool],
):
"""Updates the Q-value of an action."""
future_q_value = (not terminated) * np.max(self.q_values[next_obs])
temporal_difference = (
reward + self.discount_factor * future_q_value - self.q_values[obs][action]
)
self.q_values[obs][action] = (
self.q_values[obs][action] + self.lr * temporal_difference
)
self.training_error.append(temporal_difference)
Results
Results so far have been…disappointing. The agent so far underperforms even the basic die rolling strategy! I trained it on 500,000 games of Camel Up and the results are shown below.
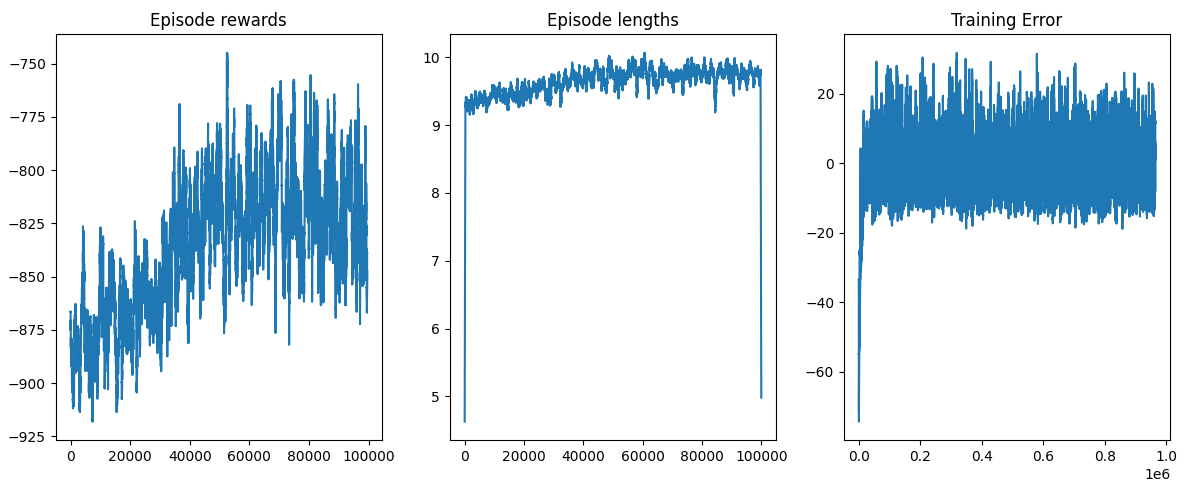
Initially the rewards improve, but then start to drop off again. The win rate of the agent was also abysmal at just 5.46%. There are a few reasons I believe are to blame for this poor performance:
- Large observation space: The observation space is simply huge – more on this in an upcoming blog post. The positions of each camel on the track, the betting tile availability, and the stack ordering all have many combinations. 500,000 games is simply not enough to see sufficient board states and infer the rewards of each action. Either I’ll need to train it for more games, be smarter about building the Q-table, or use a different approach.
- Incorrect hyperparameters: My experiences with machine learning models is that they are very sensitive to the parameters of the model. Playing around with the learning rate and discount factors in the model will improve performance. Performing a grid search on these parameters could be a useful step forward.
- Incorrect rewards: I’ve used a very simplistic reward being the player’s score, with a bonus for winning. This is probably too simple a model, and nudging behaviours I want to see may be a better solution.
Summary
What are the takeaways? Well, I hope you have a better understanding of reinforcement learning and how we can apply it using the gymnasium library. I also hope that sharing my progress (and failures!) will help your own learning!
What’s next? I think spending some time focusing on the representation of the game state will be a fruitful exercise. I’ll lay that out in the next article, and we’ll see how much more compact we can make it!
Make sure you click subscribe to get notified when the next article drops!
Leave a Reply